
Survivorship bias 是机器学习里常见但又容易被忽略的坑。
在学术研究时,我们都假设训练集和测试集是独立同分布的。在工业应用时,我们会拿离线日志数据做调研,在模型定版后,将离线数据做训练集去训练一个模型,然后部署上线,线上的请求就是我们的测试集。
但线上请求的分布跟我们离线日志数据往往是不满足独立同分布的,这就会引起 Survivorship bias,常见的影响和场景如下。
离线评估不准
由于离线测试集和在线测试集分布不一致,造成离线效果和线上效果无法对齐,详见 「离线AUC和线上CTR」。
马太效应
常见的一个场景为,用户点击了一个物料后,推荐系统就给他一直推荐,产生严重的马太效应。
当年做推荐系统时,被很多朋友吐槽过,但是在离线数据里,用户就是点这类东西多,模型也就学出你喜欢这些。
这个问题靠单个 model 优化很难解,需要配合 policy 一起来做,E&E 就是一个不错的选择,详见 「Explore-Exploit怎么做」。
猫鼠游戏
在反欺诈里,一部分场景为事中拦截,即模型识别出来为欺诈行为后直接中止后续流程。
这种场景,需要特别小心,Survivorship bias 很隐秘,但是影响挺大的,debug 周期较长。我们拿申请反欺诈场景为例展开看一下,下面是一个简化版的流程图。
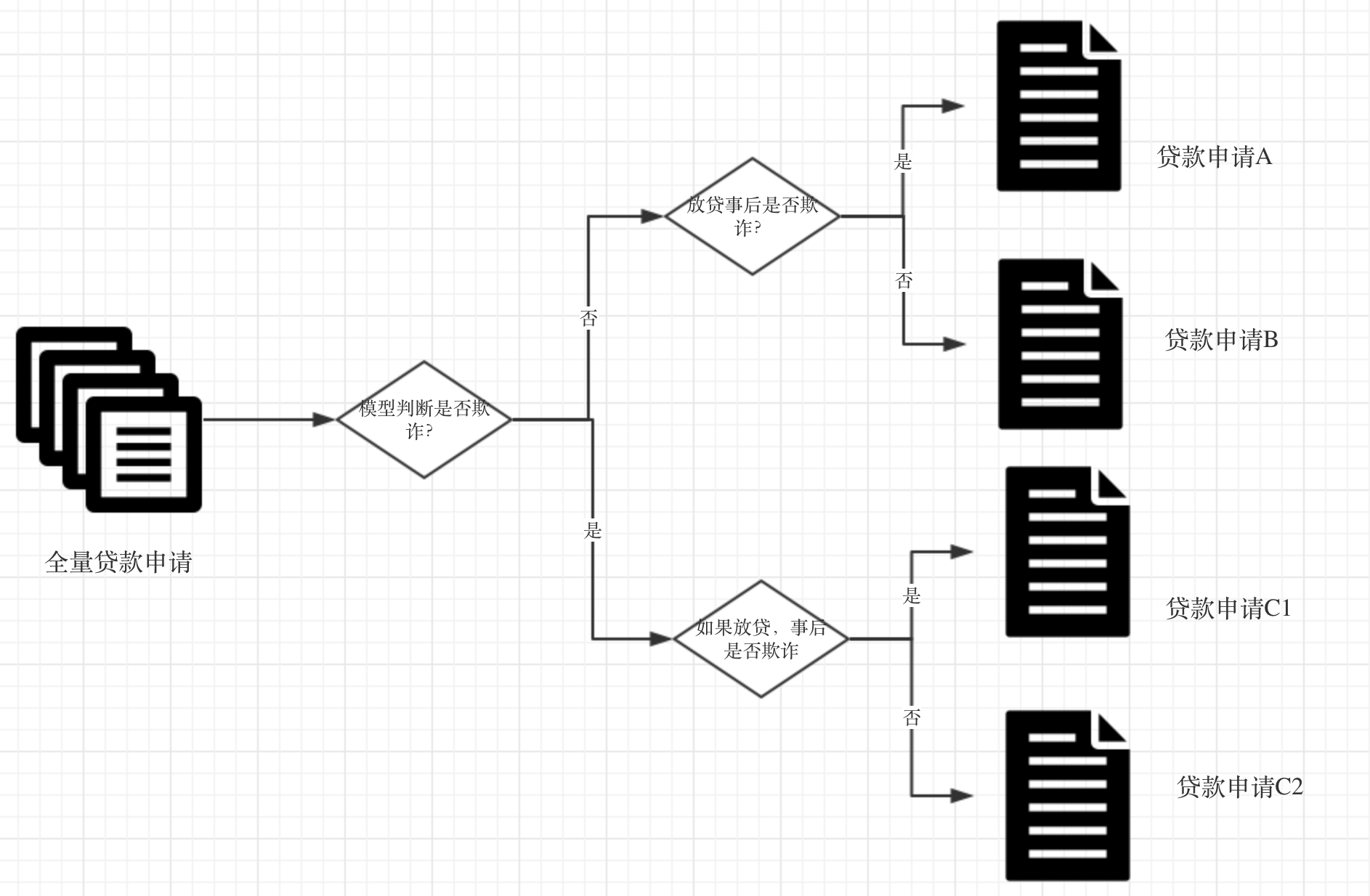
在离线数据中,我们有 A、B、C 三类申请数据(由于 C 类用户没有真实放贷,所以无法区分 C1 和 C2),由于 C 类数据是没有标注的,所以拿 A、B 来构建样本,假设学出来的模型非常牛逼,可以把 A 都拦下来同时把 B 都放过,但是上线后会发生什么呢?
A 类欺诈确实都被拦截了,但由于离线训练数据里没有没有 C1 类的样本数据,所以模型更新后,又出现了 C1 类欺诈。更近一步看,因为被拦截,所以后面产生的数据里不会有 A 类欺诈了,再次更新模型后,又无法拦截 A 了。欺诈模式就这样在 A 和 C1 中来回切换,每次模型离线效果都非常牛逼,但业务的欺诈率并不一定减少。
怎么才能逃离这种困境呢,我想到的解法以下几个,但都有缺点,大家有其它想法可以反馈给我,谢谢~
- 模型迭代做串行。可以严格降低欺诈率,但误拦率也是递增的,同时工程开销也会逐步变大。
- 将 C 全部做为欺诈样本。可以严格降低欺诈率,但误拦率也是递增的。
- 随机放过一些 C 流量。产生 C1 和 C2 数据,然后训练时加权这部分数据。这会人为的增加欺诈率(起码短期内是增加的),在一些敏感的领域是很难接受的。